
Artificial intelligence with generative capabilities can produce text, graphics, and other kinds of material. Generative AI and Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) by enabling machines to generate human-like text.
Wondering about the amazing achievements of Artificial Intelligence? Come along and discover all of its incredible potential! But before anything else, have you ever considered its revolutionary successes?

The amazing thing about this technology is that it simplifies AI; anyone may use it with just a text prompt or a natural language sentence. You can achieve desirable goals without learning a language like Java or SQL; simply speak your native tongue, express your needs, and an AI model will provide a proposal. The impact and applications of this are enormous; in just a few seconds, you can create or comprehend reports, write programs, and much more.
Although generative AI models have recently generated a great deal of attention, the technology has been decades in the making, with the initial research attempts reaching back to the 1960s. Today's AI is capable of human-level cognitive tasks, such as conversation, as demonstrated by OpenAI ChatGPT and Bing Chat, which both employ a GPT model to power their web search Bing chats.
To give you some background, the earliest AI prototypes were typewritten chatbots that relied on a knowledge base that was taken from a group of experts and input into a computer. The knowledge base's responses were retrieved based on keywords found in the input text.

The use of a statistical method called machine learning in the 1990s marked a turning point in the development of artificial intelligence (AI). By allowing algorithms to recognize patterns from data without the need for explicit programming, this method completely changed the field of text analysis. By means of training on text-label pairs, machines are able to comprehend human language and classify input text according to predefined labels that indicate the intended meaning of the message as represented by a computer. Keywords that appeared in the input text activated the knowledge base's answers.
The modern era of generative AI
That's how we arrived at today's Generative AI, which is essentially a subset of deep learning.
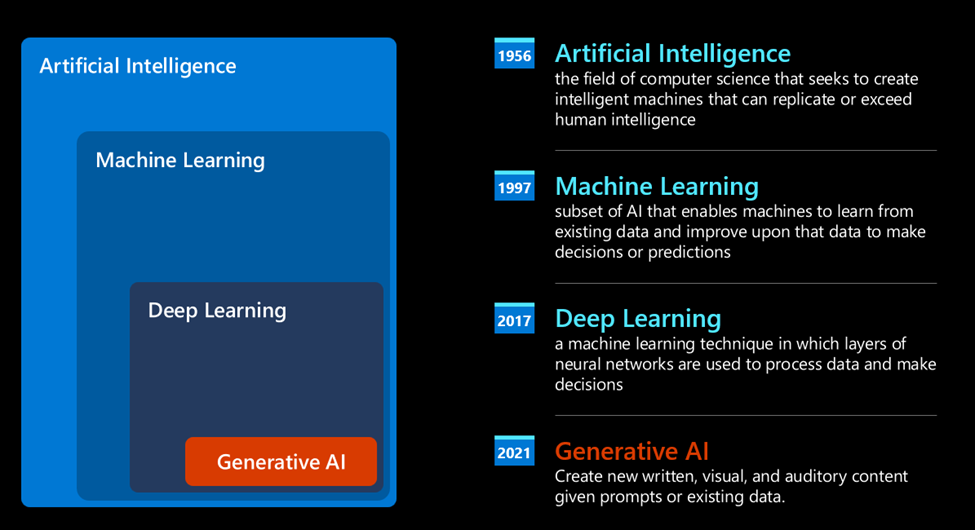
Actually, this architecture serves as the foundation for the majority of the most modern generative AI models, sometimes referred to as Large Language Models (LLMs) because of its ability to process textual inputs and outputs. These models are fascinating because they can be trained on an enormous quantity of unlabeled data from various sources, including books, papers, and websites, and they can produce grammatically accurate text with a measure of creativity for a wide range of jobs. Thus, not only did they greatly improve a machine's ability to "understand" an input text, but they also made it possible for the machine to provide an original response in human language.
Want to know more about it? Let's dive into Large Language Models
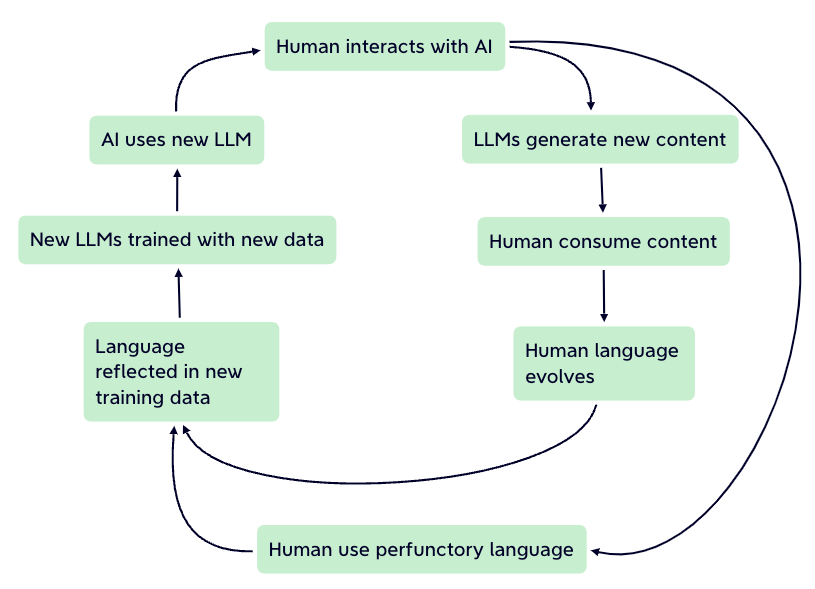
A particular kind of generative AI model called Large Language Models (LLMs) is made expressly to comprehend and produce text that resembles that of a human. To understand each aspect of language and context, these models are trained on enormous volumes of text data, frequently consisting of billions of words. Using deep learning architectures like Transformers, LLMs are able to comprehend and produce text with exceptional coherence and fluency.
With access to a large collection of pre-trained language models, including LLMs, Hugging Face is a well-known platform and library for natural language processing tasks. Thanks to the Hugging Face Transformers library, researchers and developers can easily include state-of-the-art NLP skills into their projects with an extensive collection of pre-trained models.
Key components of Hugging Face Transformers:
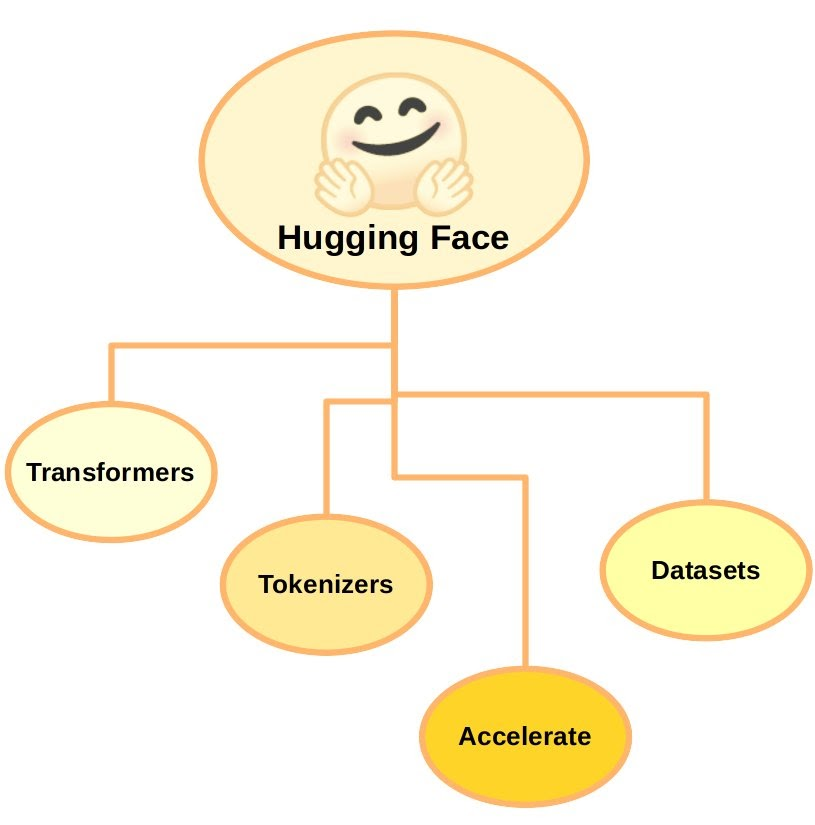
Are you curious about how the input text affects the output of the model? Let's explore...

Let's explore the code step-by-step:
Setting up the Kernel and Required Dependencies
!pip install datasets
from datasets import load_dataset
from transformers import AutoModelForSeq2SeqLM
from transformers import AutoTokenizer
from transformers import GenerationConfig
This part imports the necessary libraries. 'streamlit' is used for creating web applications, 'load_dataset' is used to load the dataset, and 'AutoModelForSeq2SeqLM' and 'AutoTokenizer' are used to load the pre-trained model and tokenizer from the Hugging Face Transformers library.
Loading the Dataset
huggingface_dataset_name = "knkarthick/dialogsum" dataset = load_dataset(huggingface_dataset_name)
We load the DialogSum dataset using the 'load_dataset' function from the 'datasets' library. This dataset contains dialogues with corresponding summaries.
Printing Example Dialogues and Summaries
example_indices = [40, 200] dash_line = '-'.join('' for x in range(100)) for i, index in enumerate(example_indices): print(dash_line) print('Example ', i + 1) print(dash_line) print('INPUT DIALOGUE:') print(dataset['test'][index]['dialogue']) print(dash_line) print('BASELINE HUMAN SUMMARY:') print(dataset['test'][index]['summary']) print(dash_line) print()
We print a couple of example dialogues along with their baseline human summaries to get an understanding of the data structure.
Loading the FLAN-T5 Model and Tokenizer
model_name='google/flan-t5-base' model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
We load the 'FLAN-T5' model using 'AutoModelForSeq2SeqLM.from_pretrained' and the tokenizer using 'AutoTokenizer.from_pretrained'. This model and tokenizer will be used for generating summaries.
Tokenization Example
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
sentence = "What time is it, Tom?" sentence_encoded = tokenizer(sentence, return_tensors='pt') sentence_decoded = tokenizer.decode( sentence_encoded["input_ids"][0], skip_special_tokens=True ) print('ENCODED SENTENCE:') print(sentence_encoded["input_ids"][0]) print('\nDECODED SENTENCE:') print(sentence_decoded)
We test the tokenizer by encoding and decoding a simple sentence to understand how tokenization works.
Generating Summaries
for i, index in enumerate(example_indices): dialogue = dataset['test'][index]['dialogue'] summary = dataset['test'][index]['summary'] inputs = tokenizer(dialogue, return_tensors='pt') output = tokenizer.decode( model.generate( inputs["input_ids"], max_new_tokens=50, )[0], skip_special_tokens=True ) print(dash_line) print('Example ', i + 1) print(dash_line) print(f'INPUT PROMPT:\n{dialogue}') print(dash_line) print(f'BASELINE HUMAN SUMMARY:\n{summary}') print(dash_line) print(f'MODEL GENERATION - WITHOUT PROMPT ENGINEERING:\n{output}\n')
We iterate through example dialogues, encode them using the tokenizer, generate summaries using the model, and decode the generated output to obtain human-readable summaries.

To deploy the functionality into Streamlit and make it user-friendly, we can follow these steps:
A complete code to deploy it on Streamlit and make it more user-friendly....
import streamlit as st
from datasets import load_dataset
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
def main():
# Load the dataset
dataset = load_dataset("knkarthick/dialogsum")
# Set up Streamlit app layout
st.title("Dialogue Summarization Explorer")
st.sidebar.title("Options")
# Select dialogue index using a dropdown
selected_index = st.sidebar.selectbox("Select Dialogue Index", range(len(dataset['test'])), index=0)
# Display selected dialogue and summary
dialogue = dataset['test'][selected_index]['dialogue']
summary = dataset['test'][selected_index]['summary']
st.subheader("Selected Dialogue")
st.write("**Dialogue:**")
st.write(dialogue)
st.write("**Baseline Human Summary:**")
st.write(summary)
st.write("---")
# Add text input for custom dialogues
user_dialogue = st.sidebar.text_area("Enter Custom Dialogue")
# Add a dropdown to select pre-trained models
model_name = st.sidebar.selectbox("Select Model", ["google/flan-t5-base", "t5-small"])
# Load selected model and tokenizer
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Generate model summary
if st.sidebar.button("Generate Model Summary"):
if user_dialogue:
dialogue = user_dialogue # Use custom dialogue if provided
inputs = tokenizer(dialogue, return_tensors='pt')
output = tokenizer.decode(
model.generate(
inputs["input_ids"],
max_length=50,
)[0],
skip_special_tokens=True
)
st.subheader("Model Generated Summary")
st.write(output)
if __name__ == "__main__":
main()
We first set up the Streamlit layout, including options for selecting a dialogue index, entering custom dialogues, and choosing a pre-trained model. Then, we loaded the selected model and tokenizer, and upon user interaction, generated a summary based on the input dialogue using the selected model.
This application provides an interactive and user-friendly interface for dialogue summarization, allowing users to explore the capabilities of large language models in summarizing conversations. With further enhancements and integrations, such as additional model options and improved user interface design, this application can be expanded to cater to a broader range of users and use cases in natural language processing tasks.
Here's the snapshot of app deployment on streamlit, local host server. This further deployment can be done on Heroku or any other platform.
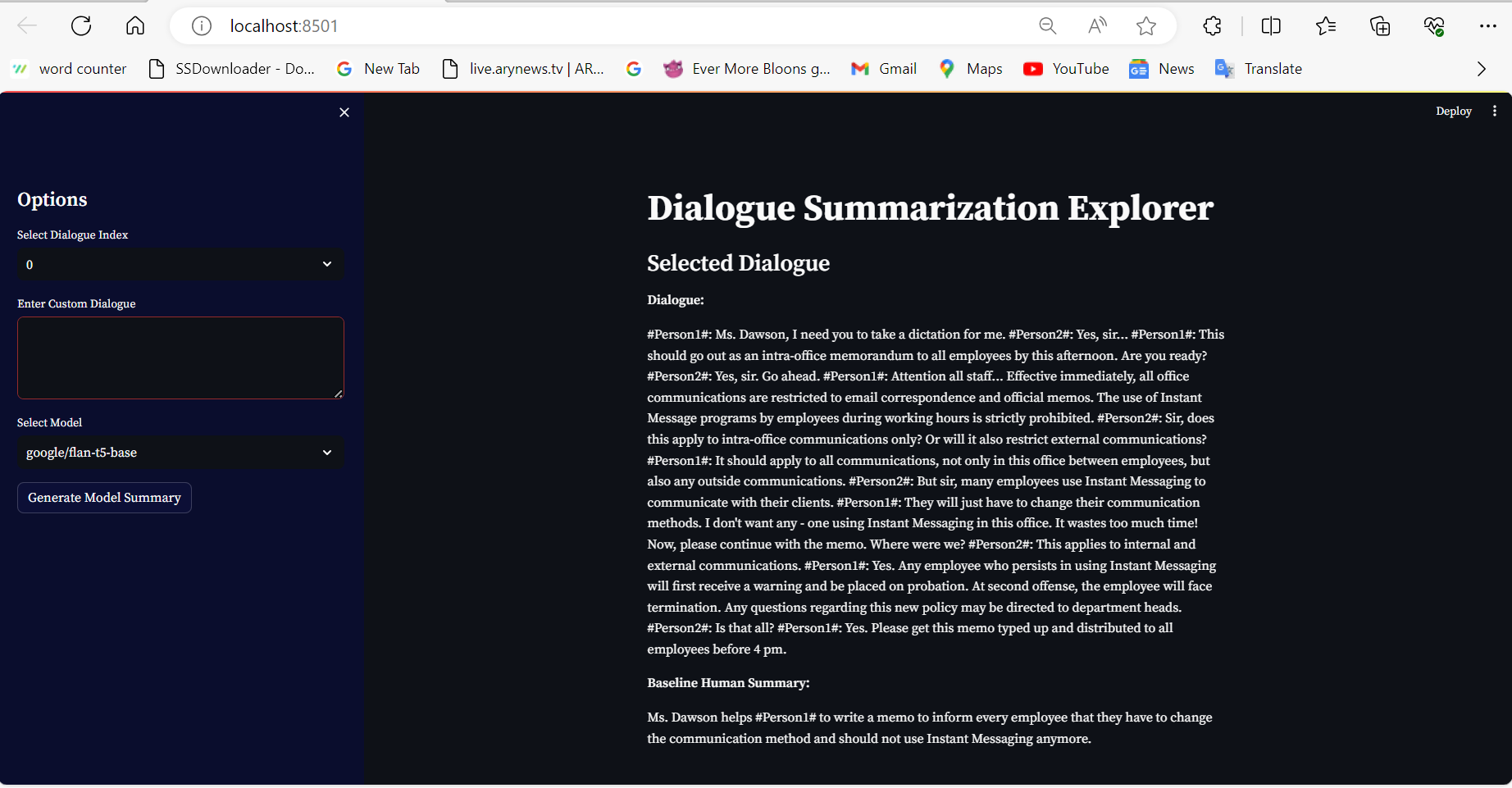
Finally, by utilizing the Hugging Face transformers library, we have successfully developed a Streamlit application for dialogue summary. Users can choose a pre-trained model, enter their own custom dialogue, pick a dialogue from a dataset, and utilize the model they've chosen to generate a summary.

Jan. 10, 2024, 5:41 a.m.
Jan. 1, 2024, 4:34 p.m.

Dec. 22, 2023, 3:02 a.m.

April 21, 2021, 6:08 p.m.